很简单的一段JavaScript代码,添加在网页中就可以了,网页中就不会再显示错误了。
貌似只有IE才会报错。
<script language="JavaScript">
function killErrors() {
return true;
}
window.onerror = killErrors;
</script>
很简单的一段JavaScript代码,添加在网页中就可以了,网页中就不会再显示错误了。
貌似只有IE才会报错。
<script language="JavaScript">
function killErrors() {
return true;
}
window.onerror = killErrors;
</script>
相信不少站长都听说过站长世界webmasterworld.com这个论坛。这是世界上最著名的站长们聚集的地方,谈论各种与网站有关的话题,包括搜索引擎优化,网络营销,网站建设的技术问题,电子商务等等。
站长世界的创始人Brett Tabke,是搜索引擎优化领域里教皇级的人物。据说他以前是经常使用和实验各种作弊手段的人物,当然他现在已经改邪归正了,至少表面上看起来如此。
近些年,他在站长世界里的帖子并不是很多,而且都非常简短。但无论他帖什么,往往都被追捧。因为他所管理的网站涉及面之宽,他本人所亲身认识的各个搜索引擎和各大电子商务公司的高层人物之多,以及他在网络世界里的权威地位之高,使他的话不得不被重视。
他有一篇非常著名的关于Google排名优化的文章,标题是”十二个月内,仅仅依靠Google打造成功网站“。
这篇文章写于2002年2月3号,到目前为止,这篇文章还是被奉为Google排名优化的圣经。所有资深的搜索引擎专家无不对这篇文章推崇倍至,而且 Brett Tabke也多次骄傲的声明,就算过了四年时间,历尽了多次Google更新和Google算法的改变,他的这篇Google排名优化文章还 是没什么好改动的。
我简单的搜索了一下有没有中文译本,竟然没有找到。当然也可能有人翻译了,而我没有找到。不过,这篇文章太重要了,所有对搜索引擎排名感兴趣的人不得不读。所以我在这里把要点翻译出来供大家参考。 继续阅读
搜索引擎都有自己的“机器人”(robots、bot),通常也叫做“蜘蛛”和“爬虫”(spider),并通过这些 robots 在网络上沿着网页上的链接(一般是http和src链接)不断抓取资料建立自己的数据库。
对于网站管理者和内容提供者来说,有时候会有一些站点内容,不希望被 robots 抓取而公开。为了解决这个问题,robots 开发界提供了两个方法:一个是 robots.txt,另一个是 robots meta 标签。下面将对这两种方法进行详细的介绍。
robots.txt 是一个纯文本文件,通过在这个文件中声明该网站中不想被 robots 访问的部分,这样,该网站的部分或全部内容就可以不被搜索引擎收录了,或者指定搜索引擎只收录指定的内容。
当一个搜索机器人访问一个站点时,它会首先检查该站点根目录下是否存在 robots.txt,如果找到,搜索机器人就会按照该文件中的内容来确定访问的范围,如果该文件不存在,那么搜索机器人就沿着链接抓取。
robots.txt 必须放置在一个站点的根目录下,而且文件名必须全部小写。
如 www.i0554.com,根目录下的 robots 就是 http://www.i0554.com/robots.txt 继续阅读
首先介绍一下html与htm
关于HTML,HTML(HyperTextMark-upLanguage)即超文本标记语言,是WWW的描述语言。设计HTML语言的目的是为了能把存放在一台电脑中的文本或图形与另一台电脑中的文本或图形方便地联系在一起,形成有机的整体,人们不用考虑具体信息是在当前电脑上还是在网络的其它电脑上。我们只需使用鼠标在某一文档中点取一个图标,Internet就会马上转到与此图标相关的内容上去,而这些信息可能存放在网络的另一台电脑中。 HTML文本是由HTML命令组成的描述性文本,HTML命令可以说明文字、图形、动画、声音、表格、链接等。HTML的结构包括头部(Head)、主体(Body)两大部分,其中头部描述浏览器所需的信息,而主体则包含所要说明的具体内容。
关于HTM,实际上HTM与HTML没有本质意义的区别,只是为了满足DOS仅能识别8+3的文件名而已,因为一些老的系统(win32)不能识别四位文件名,所以某些网页服务器要求index.html最后一个l不能省略。MSIE能自动识别和打开这些文件,但编写网页地址的时候必须是完全对应的,也就是说index.htm和index.html是两个不同的文件,对应着不同的地址。值得一提的是UNIX系统中对大小写敏感,不吻合的话就可能报没有文件或者找不到文件。 继续阅读
1.VB访问数据库的原则
总则:具体问题具体分析,根据具体的环境、条件、要求而采用适当的方案
*代码的重用和运行的效率
例如:通过使用ODBC数据源连接数据库的方法,可在变换多种数据库类型的情况下,而不用频繁修改代码。用VBSQL通过DB-Library就做不到。而ODBC接口并不是VB访问数据库运行效率最高的方法。同样,同是使用ODBC接口的ADO的效率要高于RDO
*实现的简便性,易维护性
如果一种方法实现起来很复杂,工程的开发必然造成人力物力的浪费,同时这样设计出来的应用程序只会支持起来更复杂或维护时更困难。例如:本地需要访问ISAM或Jet类型数据源,那么就使用DAO/Jet,而没有必要使用通过ODBC的方法。RDC实现起来要较RDO更容易
*安全性原则
报这一条应根据环境和条件决定。例如局域网的网络安全性要好于广域网因而可直接利用数据控件如DC,这样实现起来方便快捷,而广域网需要大量的错误捕获,如用RDC就不如用RDO易控制错误。 继续阅读
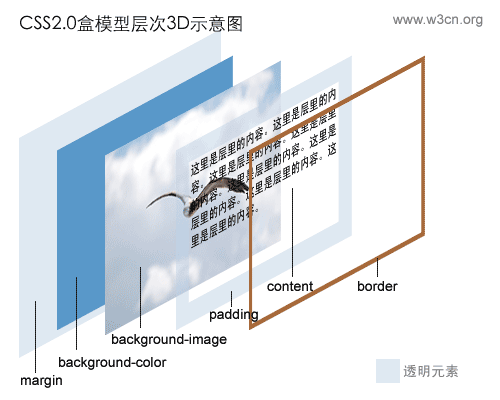
边框属性(border)用来设定一个元素的边线。
边距属性(margin)是用来设置一个元素所占空间的边缘到相邻元素之间的距离。
间隙属性(padding)是用来设置元素内容到元素边界的距离。
这三个属性都属于CSS中box类型的属性。下面两个图很形象的说明了,我也是刚刚才看懂。


近期评论